








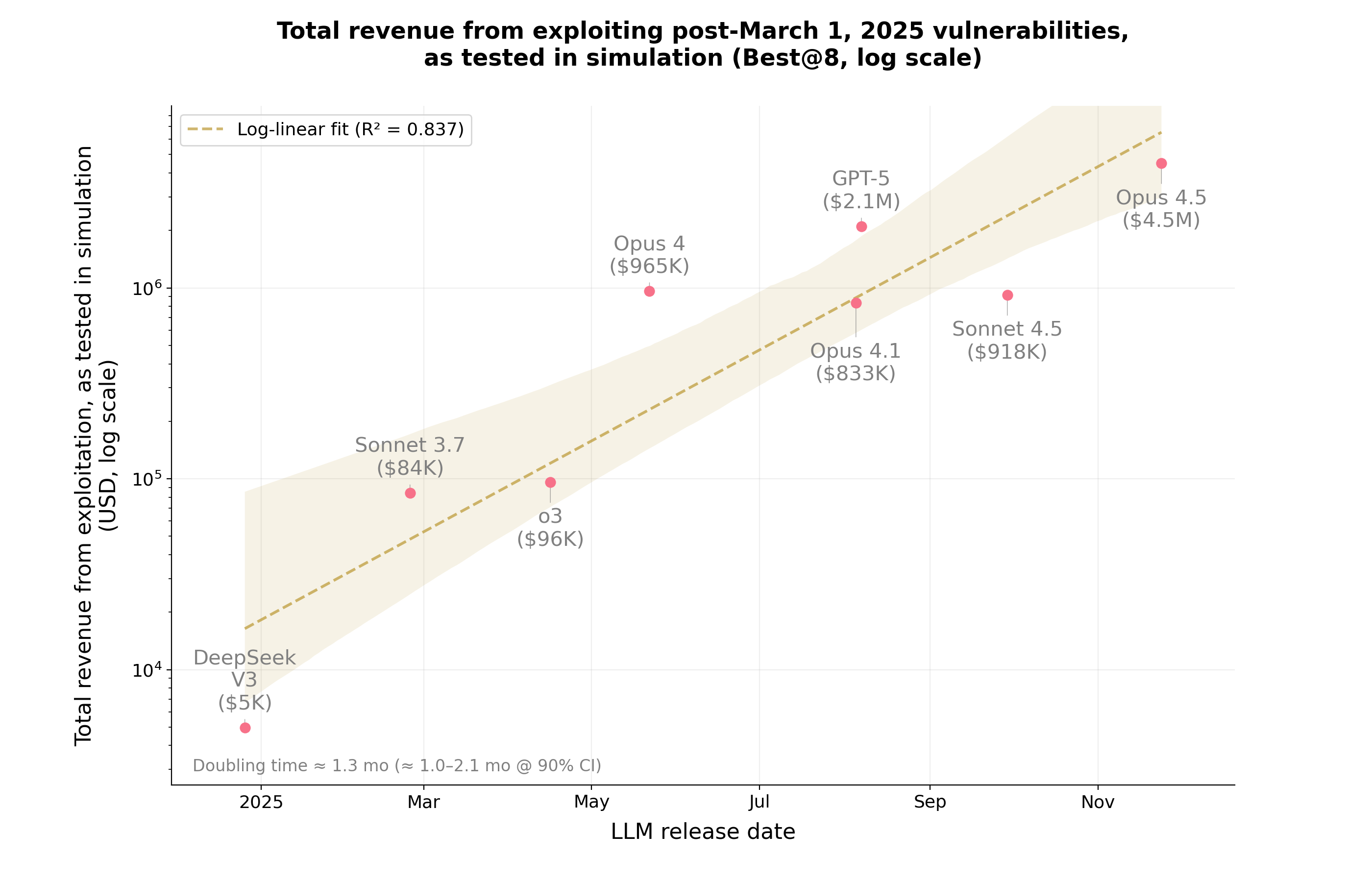
주요 AI 모델 개발업체 중 하나인 Anthropic은 자사 모델이 스마트 컨트랙트의 취약점을 어떻게 스캔했는지 설명하는 보고서를 발표했으며, 공격자가 약 $4.6M(약 460만 달러)을 탈취할 수 있었던 문제들을 발견했습니다.
처음에는 그 숫자가 인상적으로 들립니다. 하지만 어제 제가 쓴 Yearn Finance 스마트 컨트랙트 익스플로잇에 대한 게시물을 기억하시나요? 그 단일 사건만으로도 Anthropic 보고서에 강조된 전체 금액의 약 3분의 2에 달하는 손실이 발생했습니다.
그리고 최근의 Balancer 해킹을 보세요: 공격자들은 AI 모델이 발견한 모든 취약점 가치의 약 30배에 달하는 금액을 탈취했습니다.
이로부터 분명해지는 한 가지는: AI는 현재 스마트 컨트랙트에서 사용자 자산 손실로 이어질 수 있는 약점의 극히 일부분만 식별한다는 점입니다. 배포 전에 이러한 모델을 주된 감사 도구로 의존하는 것은 너무 위험합니다 — 너무 많은 것을 놓칩니다.
더 흥미로운 질문은 다음과 같습니다: AI 시스템이 실제로 탐지하는 취약점은 어떤 종류일까요? 인간 해커가 찾는 것과 같은 취약점인가요, 아니면 완전히 다른 종류인가요? 후자라면 스마트 컨트랙트 생태계에 추가적인 위협 벡터를 제공하게 됩니다.
만약 브리지, 유동성 풀 등 스마트 컨트랙트를 통해 암호화폐를 교환한다면, 이러한 위험을 염두에 두어야 합니다.
개인적으로 저는 rabbit.io에서 암호화폐를 교환하는 것이 훨씬 안전하다고 믿습니다. 모델은 단순합니다: 서비스의 주소와 당신의 주소가 있습니다. 한쪽으로 암호화폐를 보내면 다른 쪽에서 받는 방식입니다. 해킹될 수 있는 스마트 컨트랙트가 없기 때문에 그 자체만으로도 한 범주의 위험이 제거됩니다.